In this project, we will go through all the stages of the lifecycle of a Machine Learning project, resulting in the development of an API deployed on Render, through which queries can be made to the records of a Steam (videogames) platform database. Additionally, a machine learning recommendation model for video games based on cosine similarity is developed, which can also be accessed through the API.
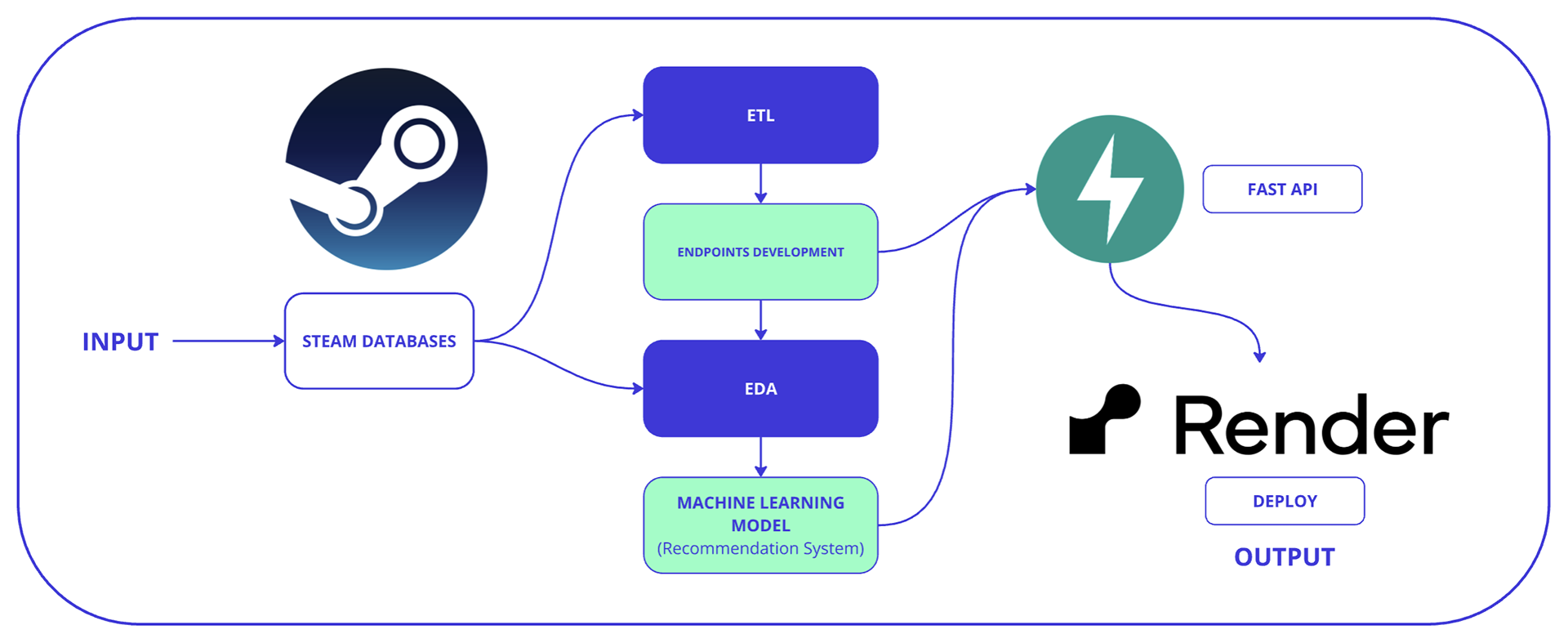
The project is divided into two parts:
Part I: Data Engineering. It starts from scratch, quickly working as a Data Engineer with data collection and extraction from files, as well as their processing, transformation, and modeling.
Part I: Data Engineering. It starts from scratch, quickly working as a Data Engineer with data collection and extraction from files, as well as their processing, transformation, and modeling.
Part II: Machine Learning. The model is created, the cleaned data is consumed, and it is trained under certain conditions. As a result, a video game recommendation system for Steam users is created, using MLOps techniques to ensure that the model and the API are scalable, reproducible, and maintainable.
↓ Tech stack

OBJECTIVES
1- Data Transformations: Read and clean the dataset, removing unnecessary columns to optimize performance, knowing that data maturity is low: nested data, raw type, no automated processes for updating new products, among other things.
2- Feature Engineering: Perform sentiment analysis on user reviews and create a new column 'sentiment_analysis'.

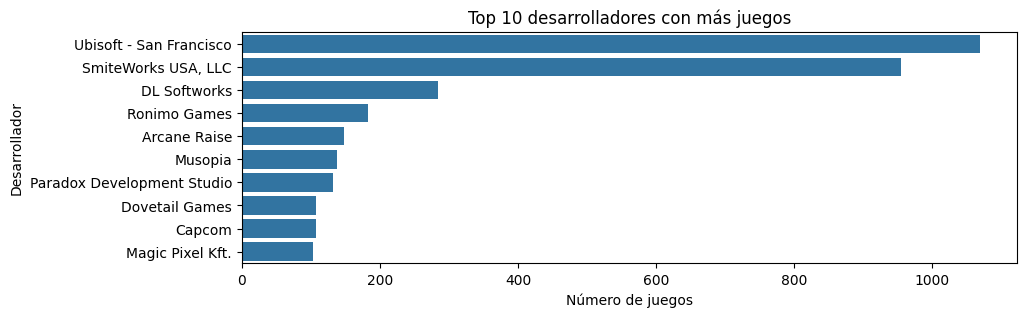
3- Exploratory Data Analysis (EDA): explore and visualize the data to gain valuable insights

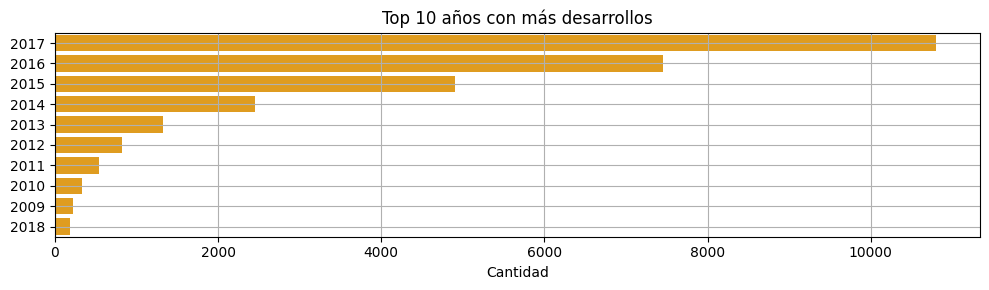
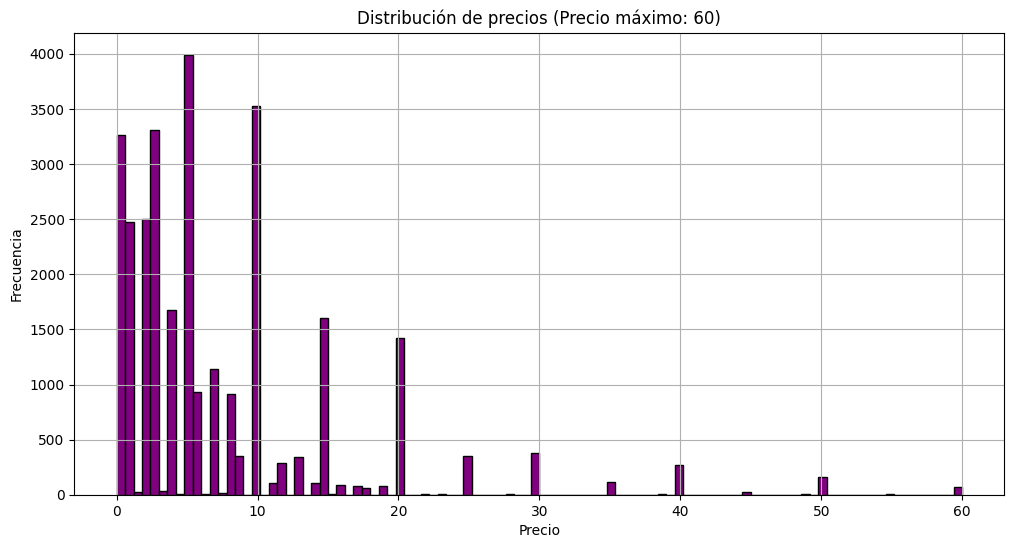
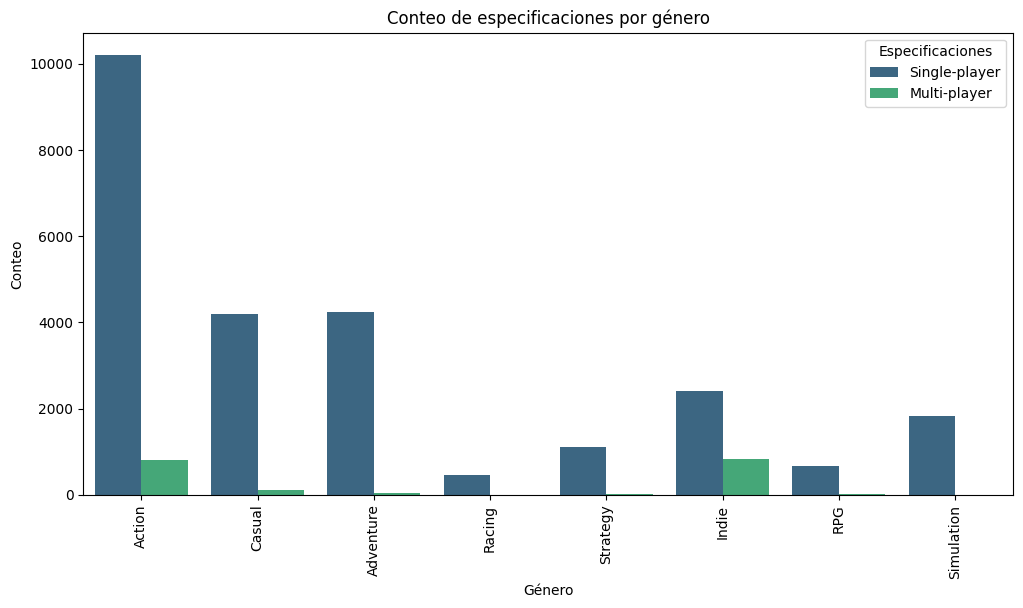
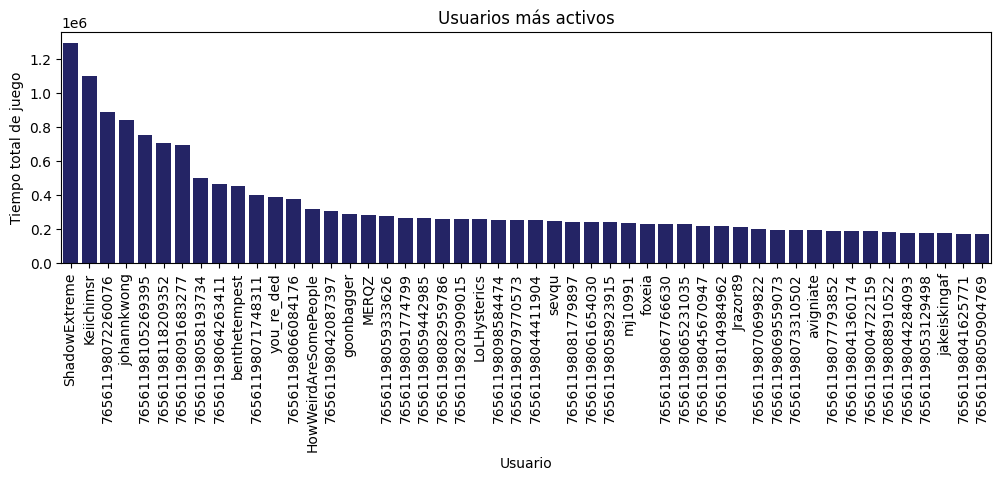

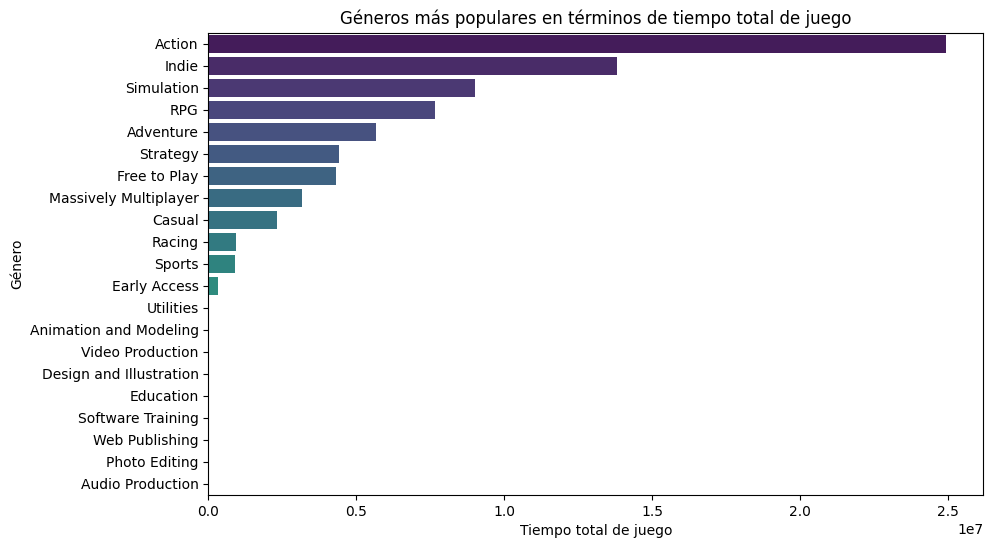
4- Machine Learning Model: develop a recommendation system based on cosine similarity: Input: Product ID / Output: List of 5 recommended games similar to the entered one
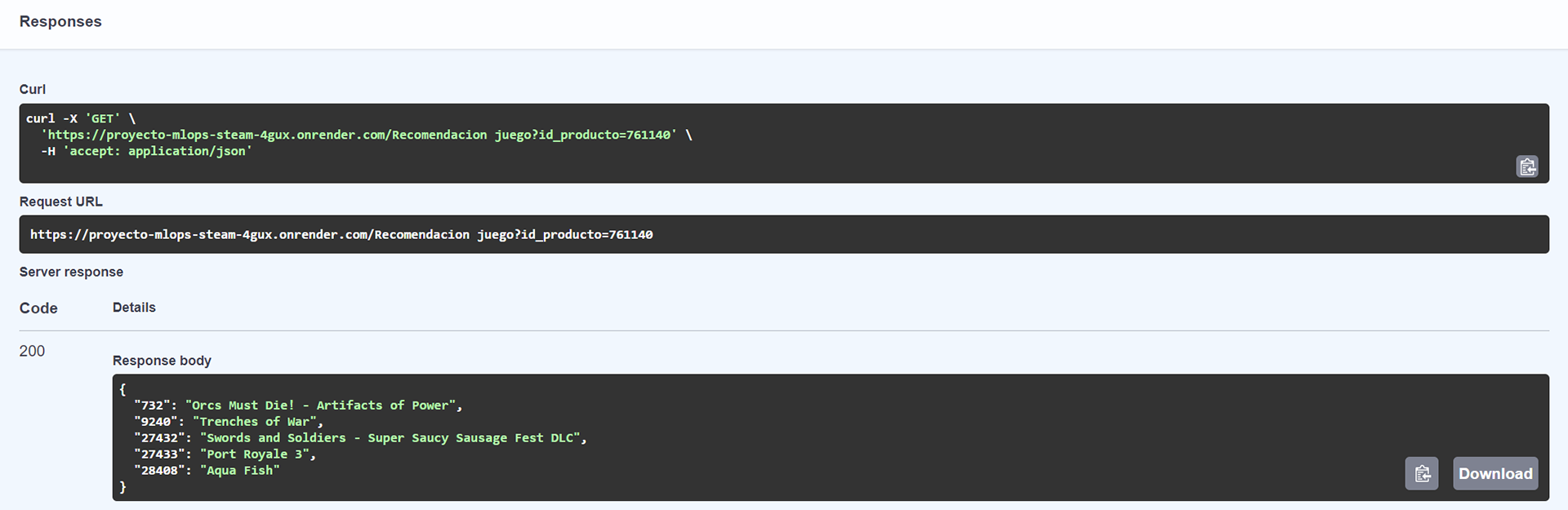
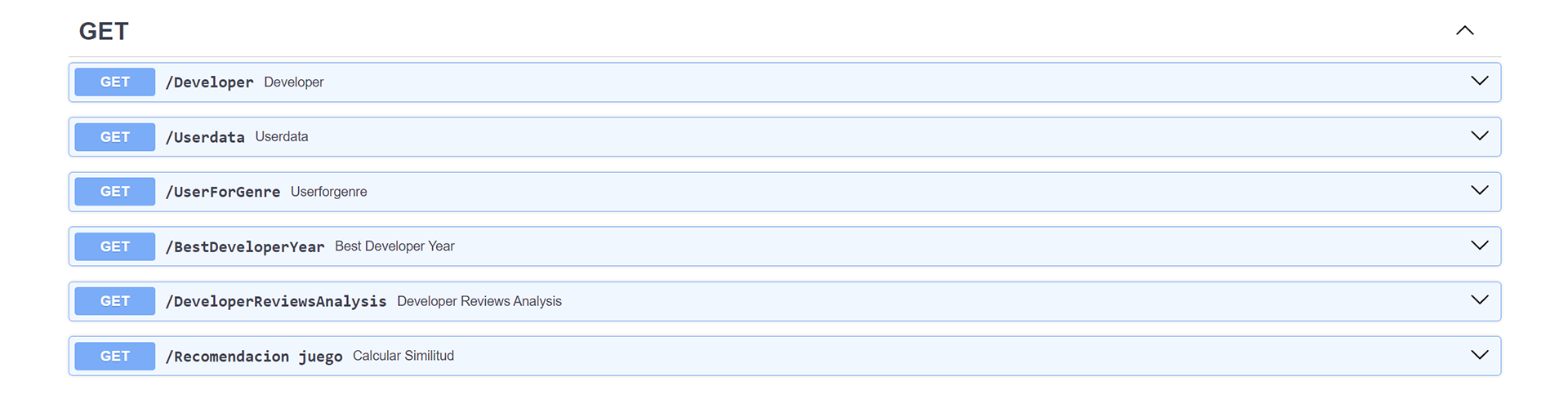
5- API Development: implement an API with FastAPI that allows querying data and recommendations.
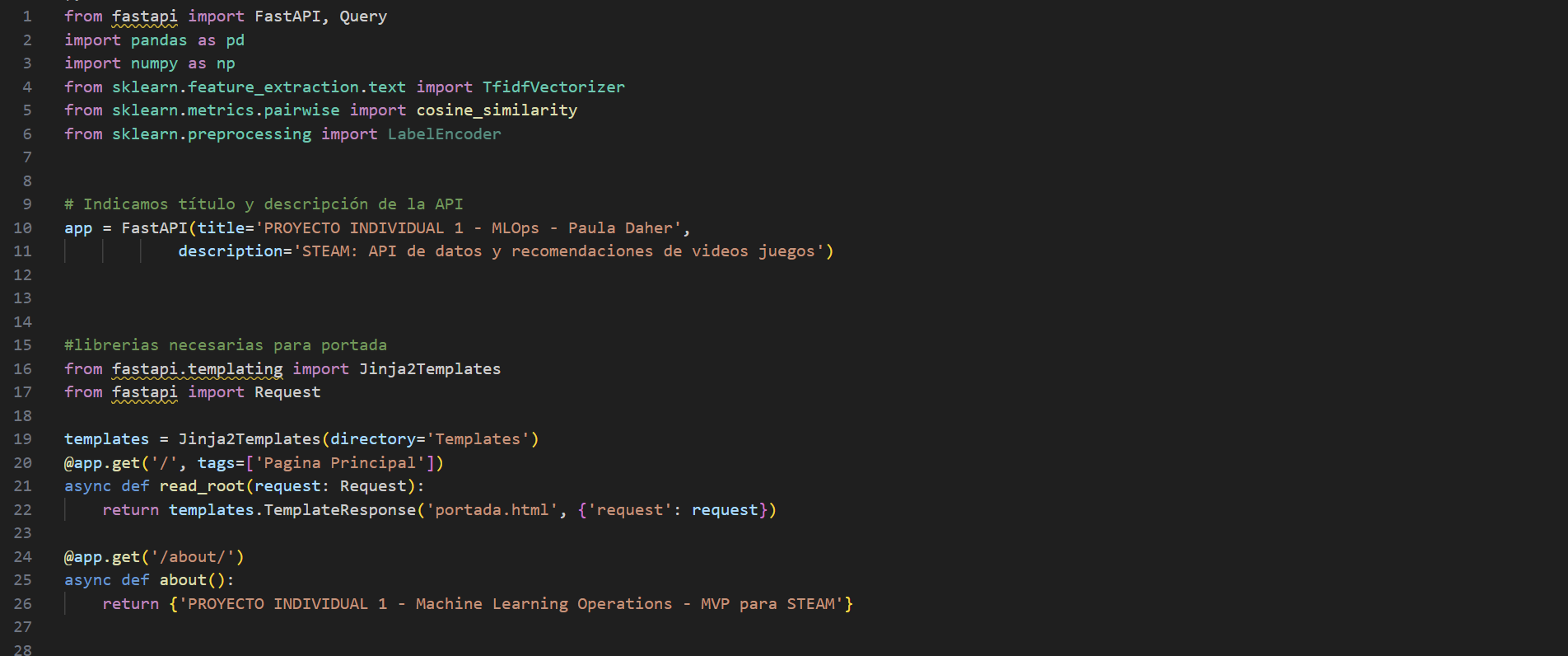
6- Deployment: deploy the API on a web service to make it publicly accessible